Venkat Ramnan Kalyanakumar

Portfolio Website
Hi, I am Venkat !!
I am a graduate student (M.S. in computer science) at Oregon State University. Striving to contribute clean code and robust software engineering capabilities, with a keen interest in opportunities within machine learning, computer vision, or data science.
🌟 Looking for Full-Time Opportunities 🌟
Education
| Degree | University | Duration |
|---|---|---|
| M.S., Computer Science | Oregon State University | Sep 2022 - present |
| B.Tech., Electronics and Communication | PES University | June 2022 |
Skills
Other Skills (things I have **not** used extensively as above)
- C++
- Docker
- MLFlow
- ROS
- Unity
- OpenAI Gym
- Postgres
Machine Learning (research) interests
- Computer Vision (3D / 2D)
- Deep learning
- Reinforcement Learning
- Robotics (ROS)
Experience
![]() Graduate Research Assistant @ Oregon State University (Sep 2022 - Present)
Graduate Research Assistant @ Oregon State University (Sep 2022 - Present)
- Developed computer vision‑based trajectory prediction algorithms, achieving 92% accuracy in detecting physics violations across diverse scenarios for the Passive Violation Of Expectation challenge of
 DARPA Machine Common Sense Challenge.
DARPA Machine Common Sense Challenge. -
Currently working on Sim to real experiments and point cloud based object detection (3D Vision). Working on TR3D (Point cloud 3D object detection) for custom data (for all rotations across the axes).
Experiments
- Research focused on capturing inter‑object and object‑environment interactions at long ranges, exploring 3D and point cloud versions. - Leveraged the Region Proposal Interaction Network to enhance model performance, yielding remarkable results on our custom MCS DARPA dataset - Used Motion Indeterminacy diffusion model for diverse trajectory prediction for intuitive physics experiments.
![]() Robotics intern @ Nokia Bell Labs (NJ) (Jun 2023 - Aug 2023)
Robotics intern @ Nokia Bell Labs (NJ) (Jun 2023 - Aug 2023)
- Implemented a state‑of‑the‑art machine vision anomaly detection system, achieving a 91.3% Pixel ROC score by customizing PaDiM and PatchCore models for a custom PCB dataset, ensuring precise anomaly detection. This was a part of the FlexForce Digital Twin and Metaverse based system.
- Developed an end‑to‑end pipeline for deploying an Anomaly Detection (AD) overseer app for Nokia Chennai Factory. Successfully deployed the AD App in real time.
- Collaborated on efficient optimization strategies to improve PaDiM’s performance on the custom PCB dataset.
Research intern @ Indian Institute of Science (Jul 2021 - Dec 2021)
- Developed Constraint Aware Deep Learning models for resource allocation in Device to Device (D2D) communication and introduced Lagrangian‑based neural networks to solve optimization problems with constraints in a data‑driven manner to achieve an impressive 80 % accuracy.
![]() Student intern @ Nokia (Feb 2021 - Feb 2022)
Student intern @ Nokia (Feb 2021 - Feb 2022)
- Setup ROS, deployed gazebo 3D models for environment and turtlebot sim, created a map for Robot Navigation using teleop.
- Object Detection using SSD Mobilenetv3 and YOLOv3(Python:OpenCV,Tensorflow, C++(basic), Linux)
- Delivered functioning turtlebot that mapped areas of Nokia Bangalore
- Team Awarded ”Best Student Bell Labs Research project” at 2021 Nokia University Conclave
Publications
- Rajasekar Mohan, K Venkat Ramnan, Manikandan J (2022). Predicting The Throughput Of Next Generation IEEE 802.11 WLANs In Dense Deployments.Procedia Computer Science, 203, 24‑31.paper
- F. Wilhelmi, D. Góez, P. Soto, R. Vallés, M. Alfaifi, A. Algunayah, J. Martin‑Pérez, L. Girletti, R. Mohan, K. V. Ramnan. ”Machine Learning for Performance Prediction of Channel Bonding in Next‑Generation IEEE 802.11 WLANs.” arXiv preprint arXiv:2105.14219 (2021). paper
- K.V. Ramnan , Karthik Seemakurthy, Uthayakumar G S, Curriculum Learning for Brain Tumor Segmentation ; Presented as Poster Presentation at the 24th International Conference on Medical Image Computation and Computer Assisted Intervention (MICCAI 2021) Brain‑lesion Workshop (BrainLes) Featuring Brain Tumor Segmentation (BraTS) Challenge. PPT and video
- Mohan, R., Ramnan, K., Manikandan, J. (2021). Machine Learning approaches for predicting Throughput of Very High and EXtreme High Throughput WLANs in dense deployments. In 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT) (pp. 1‑6). paper
- Krishna, A., Arikutharam, V., Ramnan, K., Bharathi, H., Chandar, T. (2022). Dynamic Image Encryption using Neural Networks for Medical Images. In 2022 IEEE IAS Global Conference on Emerging Technologies (GlobConET) (pp. 739‑745). paper
Academic Projects
Learning-Based Motion Planning for Arbitrary Locomotive Systems
A novel motion planning framework for general locomoting systems, beyond car-like robots, integrating dynamically feasible motion primitives using Deep Deterministic Policy Gradients (DDPG) reinforcement learning and an artificial potential field for accurate learning guidance.
Major contributions are:
- Considering the motion planning problem beyond the path planning by considering the dynamically feasible motion primitives.
- Implementing The motion planning framework for general locomoting systems beyond car-like robots.
- Achieving the globally optimal path and giving accurate learning guidance by combining RL with conventional motion planning (the artificial potential field).
Explainable AI for NASA Hirise Mars Project
This project aims to build an explainable CNN model to classify Mars HiRISE images, providing insights into why the model makes certain classifications. By achieving interpretability, it will enhance trust in the model’s predictions and help identify biases and prejudices in its decisions.
Major contributions are:
- Weighted sampler and Focal loss for extremely imbalanced data.
- Implemented LIME, SHAP and GradCAM for explainability using heatmaps and class activation maps.
- Covariate shift handles using illumination (openCV LUT) and batch normalization on modified ResNet.
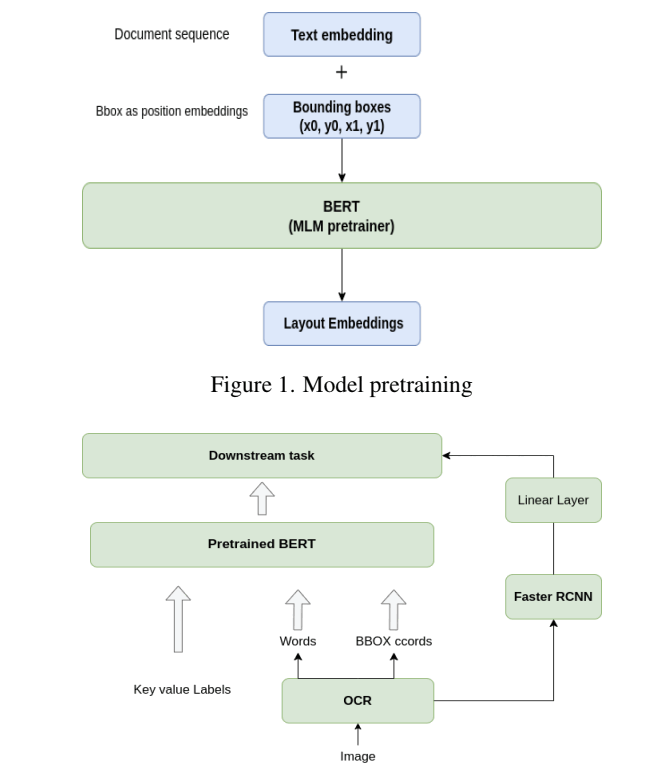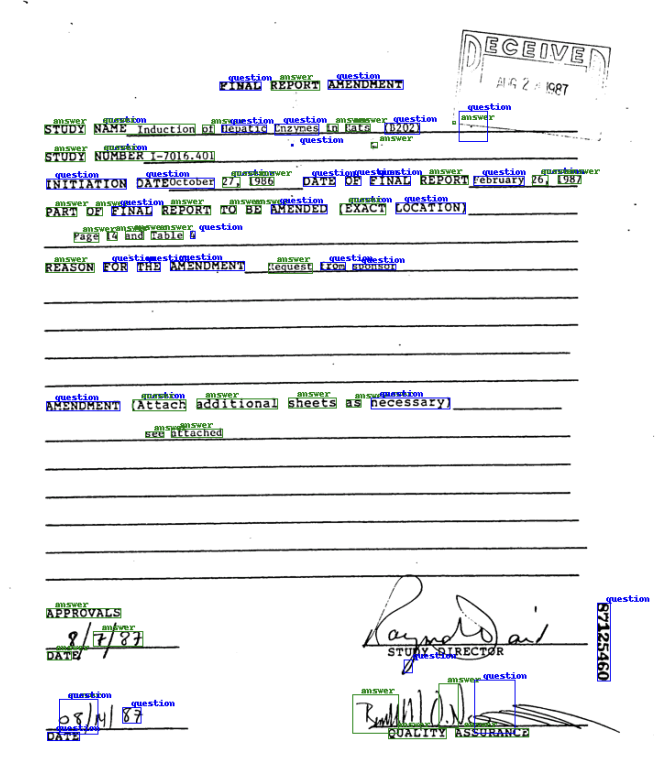
Key Value Pair Extraction from Scanned Documents
The task of text extraction from documents is commonly targeted as a computer vision problem with text postprocessing done to ensure correctness. A sub-problem in that domain is more focused on identifying key-value pairs in a scanned document in order to populate in an exist- ing database. In this project we propose a method for extracting these key-value pairs from document images usingboth layout information and textual associations. Thus, this is a multi-modal approach in which we use image embeddings from FastRCNN integrated with BERT model to combine text, layout, and image features. We create a different variant of positional embeddings and pretrain BERT using masking. This model is then fine-tuned for the downstream task of key-value pair extraction. This method has applications in information extraction and quick document analysis tasks.
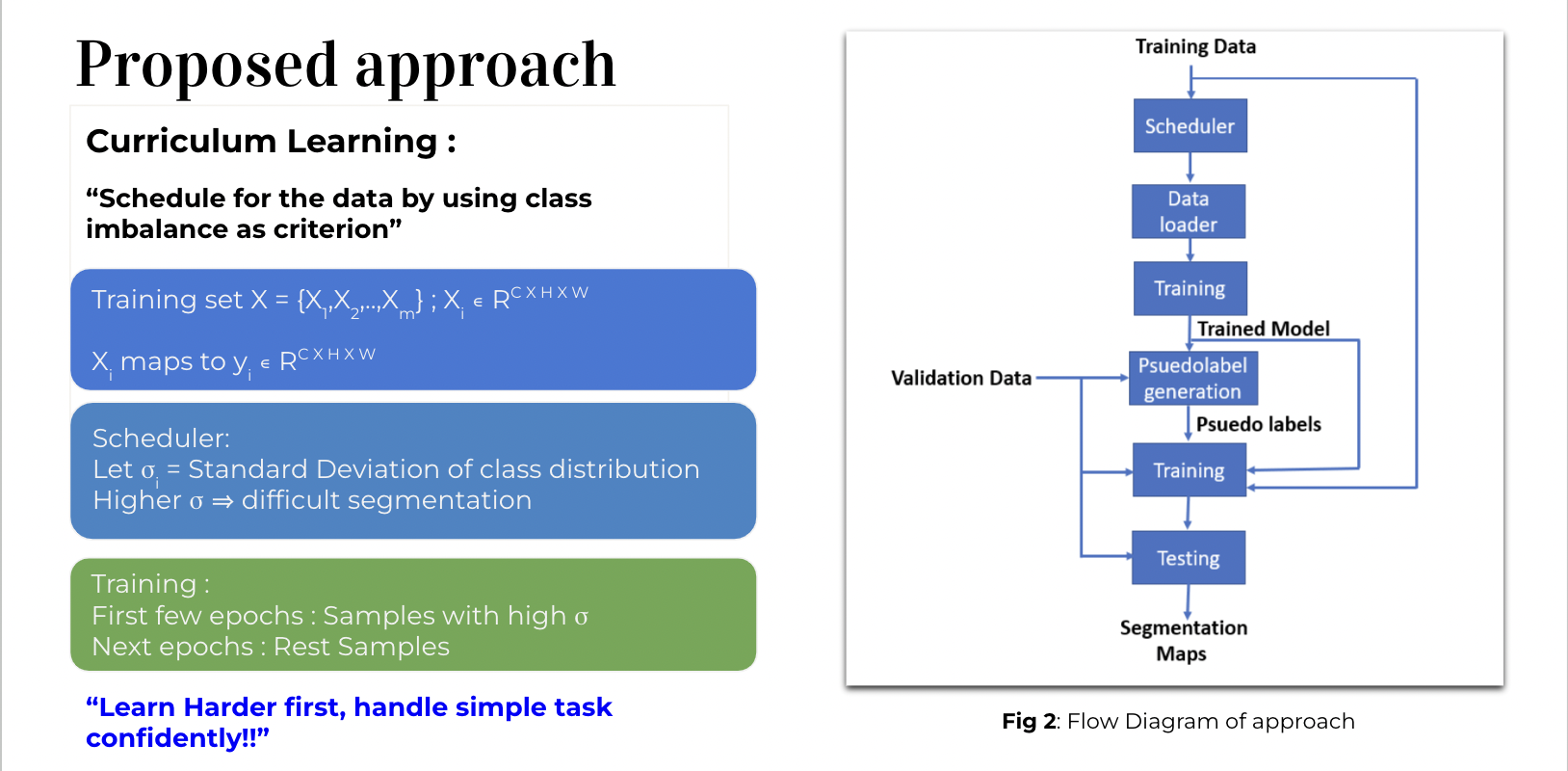
Curriculum Learning For Brain Tumor Segmentation
Curriculum learning utilizes a novel scheduling algorithm based on standard deviation of class label distribution. Input data is represented as an array with dimensions (m samples, C channels, H height, W width), each with corresponding output labels. The standard deviation of class distribution reflects the difficulty of segmentation, with higher values indicating more challenging samples. Training begins with the most difficult examples, gradually incorporating easier ones in subsequent epochs. Results demonstrate that curriculum learning achieves convergence to full data training within 40 epochs, while also reducing training time by 30% compared to standard approaches. Presented as 2022 MICCAI poster.